S08-04 Node-MySQL
[TOC]
认识数据库
为什么要使用数据库
任何的软件系统都需要存放大量的数据,这些数据通常是非常复杂和庞大的:
- 比如用户信息包括姓名、年龄、性别、地址、身份证号、出生日期等等;
- 比如商品信息包括商品的名称、描述、价格(原价)、分类标签、商品图片等等;
- 比如歌曲信息包括歌曲的名称、歌手、专辑、歌曲时长、歌词信息、封面图片等等;
那么这些信息不能直接存储到文件中吗?可以,但是文件系统有很多的缺点:
- 很难以合适的方式组织数据(多张表之前的关系合理组织);
- 并且对数据进行增删改查中的复杂操作(虽然一些简单确实可以),并且保证单操作的原子性;
- 很难进行数据共享,比如一个数据库需要为多个程序服务,如何进行很好的数据共享;
- 需要考虑如何进行数据的高效备份、迁移、恢复;
- 等等...
数据库通俗来讲就是一个存储数据的仓库,数据库本质上就是一个软件、一个程序。
常见数据库
数据库分类:
通常我们将数据划分成两类:
关系型数据库:MySQL、Oracle、DB2、SQL Server、Postgre SQL 等;
- 关系型数据库通常我们会创建很多个二维数据表;
- 数据表之间相互关联起来,形成一对一、一对多、多对对等关系;
- 之后可以利用 SQL 语句在多张表中查询我们所需的数据;
- 支持事物,对数据的访问更加的安全;
非关系型数据库:MongoDB、Redis、Memcached、HBse 等;
- 非关系型数据库的英文其实是 Not only SQL,也简称为 NoSQL;
- 相对而言非关系型数据库比较简单一些,存储数据也会更加自由(甚至我们可以直接将一个复杂的 json 对象直接塞入到数据库中);
- NoSQL 是基于 Key-Value 的对应关系,并且查询的过程中不需要经过 SQL 解析,所以性能更高;
- NoSQL 通常不支持事物,需要在自己的程序中来保证一些原子性的操作;
如何在开发中选择他们呢?具体的选择会根据不同的项目进行综合的分析,我这里给一点点建议:
- 目前在公司进行后端开发(Node、Java、Go 等),还是以关系型数据库为主;
- 比较常用的用到非关系型数据库的,在爬取大量的数据进行存储时,会比较常见;
我们的课程是开发自己的后端项目,所以我们以关系型数据库 MySQL 作为主要内容。
MySQL 介绍:
- MySQL 原本是一个开源的数据库,原开发者为瑞典的 MySQL AB 公司;
- 在 2008 年被 Sun 公司收购;在 2009 年,Sun 被 Oracle 收购;
- 所以目前 MySQL 归属于 Oracle;
MySQL 是一个关系型数据库,其实本质上就是一款软件、一个程序:
- 这个程序中管理着多个数据库;
- 每个数据库中可以有多张表;
- 每个表中可以有多条数据;
MySQL 下载/安装
第一步:下载 MySQL 软件
下载地址:https://dev.mysql.com/downloads/mysql/
根据自己的操作系统下载即可;
推荐大家直接下载安装版本,在安装过程中会配置一些环境变量;
- Windows 推荐下载 MSI 的版本;
- Mac 推荐下载 DMG 的版本;
这里我安装的是 MySQL 最新的版本:8.0.22(不再使用旧的 MySQL5.x 的版本)
Windows:
- 下载下面的,不需要联网安装;
Windows 下载的版本
Mac:
Mac 下载的版本
第二步:安装的过程
安装的过程,基本没有太复杂的操作。
有一个需要着重说明的是 MySQL8,可以采用一种更新的、安全性更高的密码和加密方式:
- 最新的加密方式有可能会被一些比较老的软件驱动不支持;
- 所以要根据情况来选择,但是我这里选择最新的加密方式了;
Windows 的安装过程:
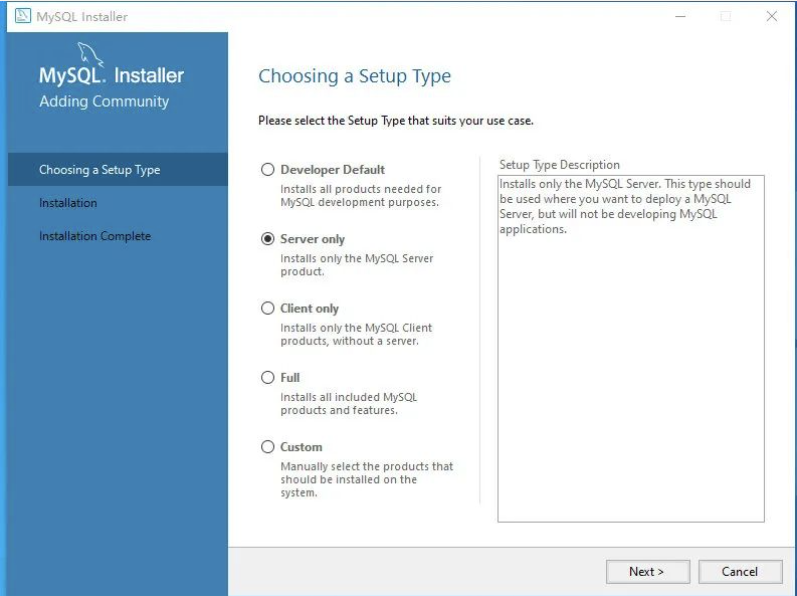
Server Only
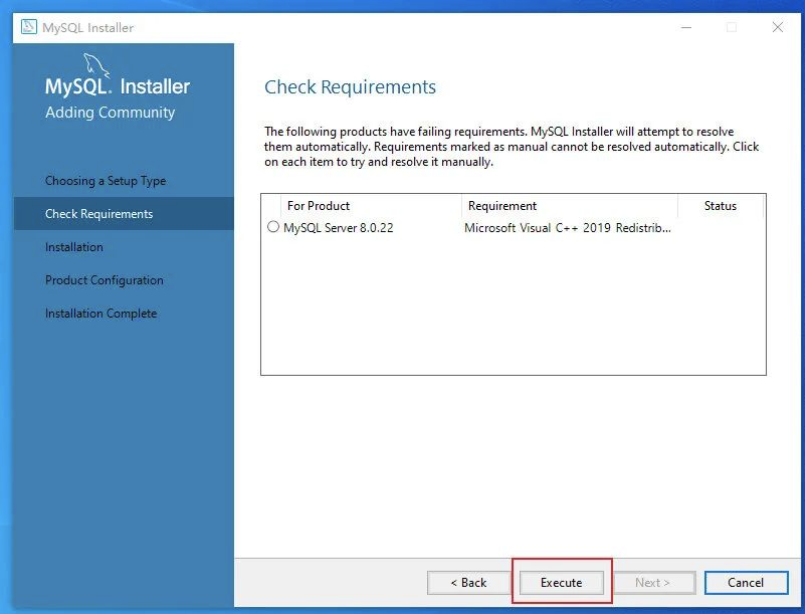
执行
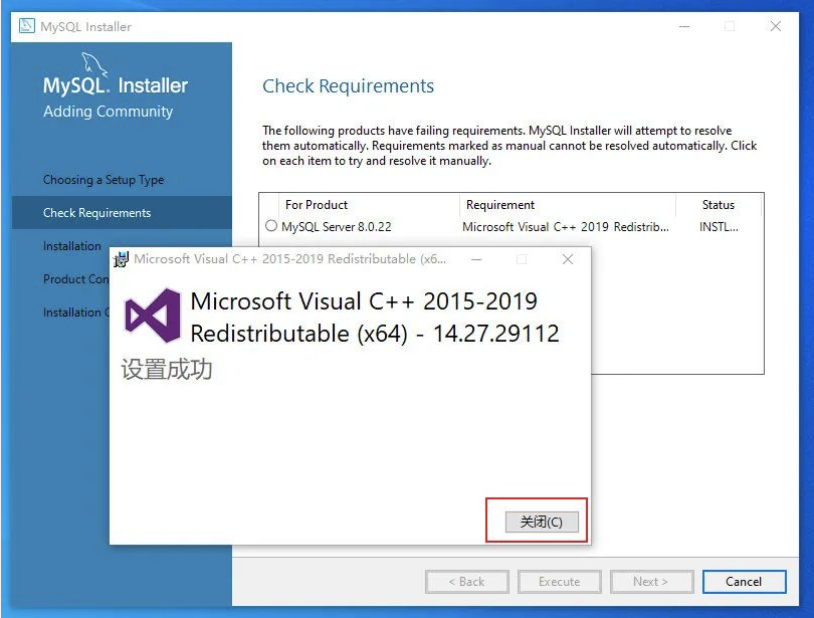
安装一个依赖
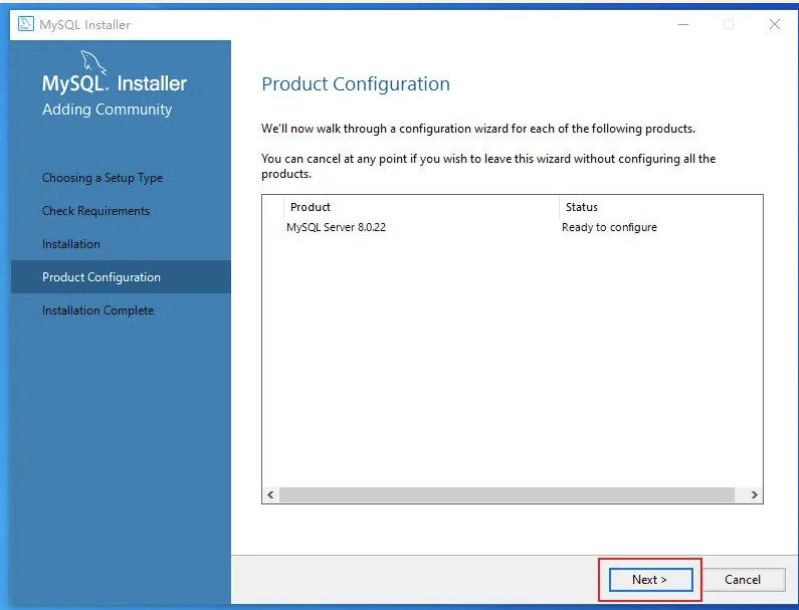
下一步
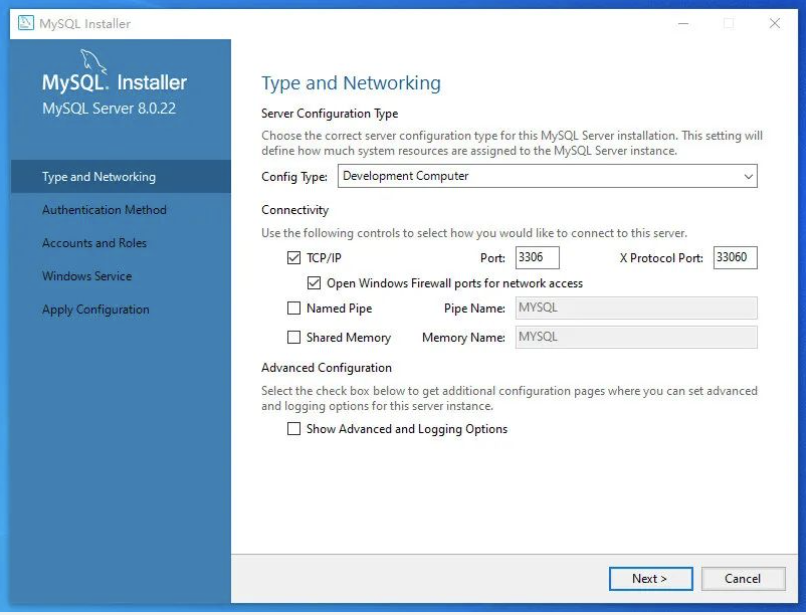
配置端口号
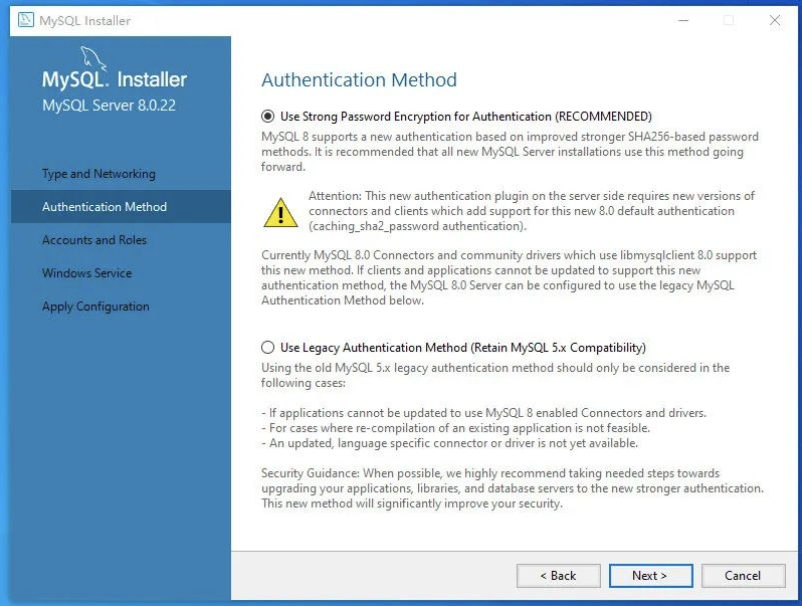
选择密码加密方式
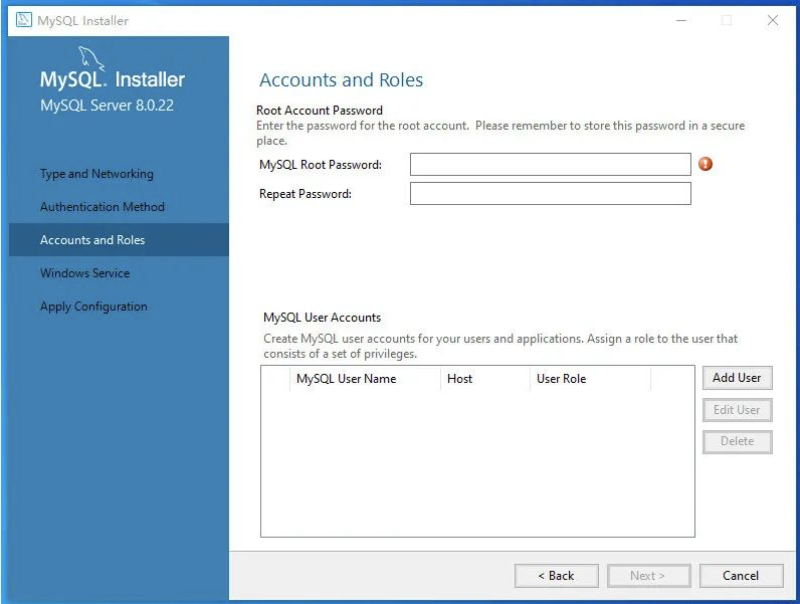
填写一个复杂的密码
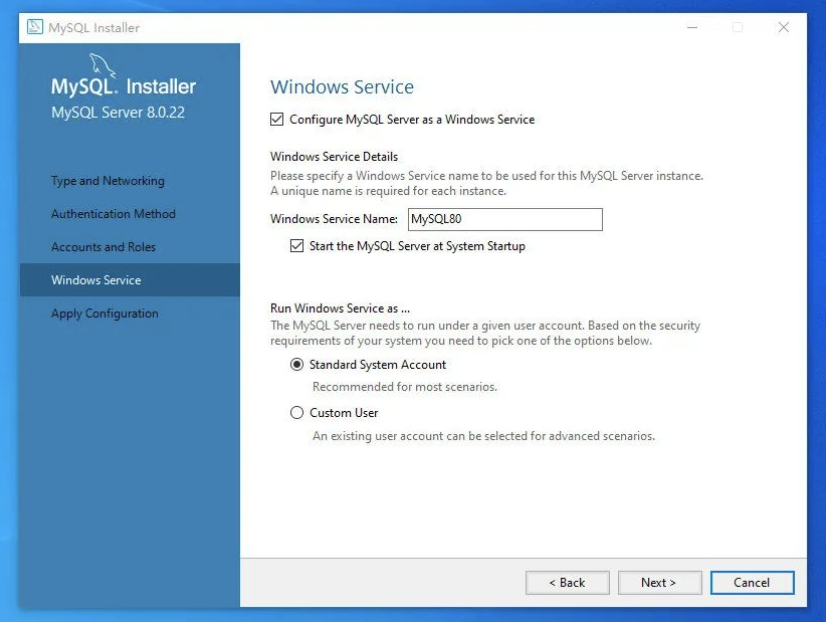
配置服务的名称
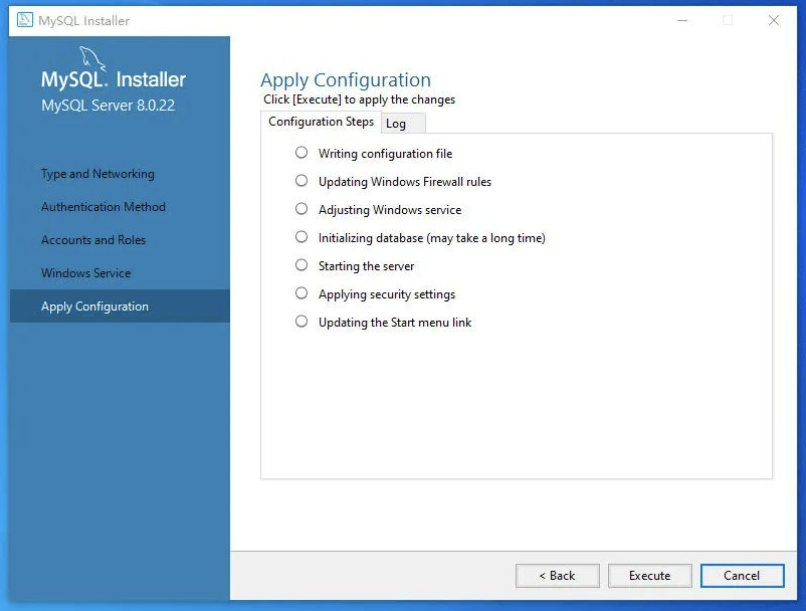
应用所有配置
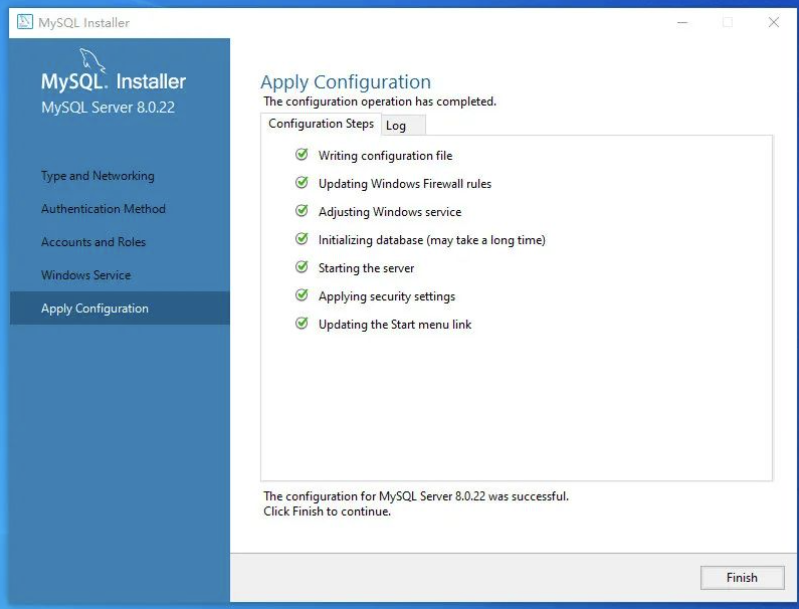
完成即可
第三步:启动 mysql
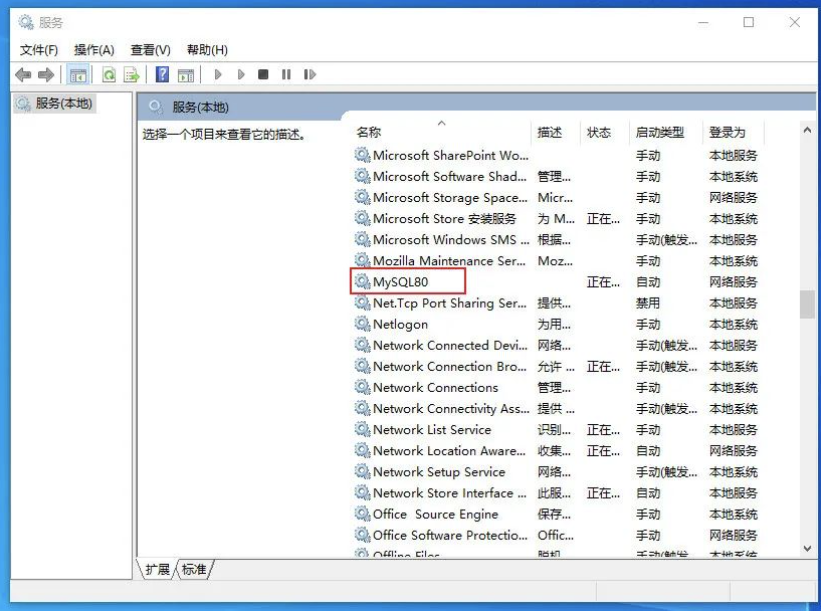
在 Windows 启动 MySQL:
在 Mac 中启动 MySQL 是在系统偏好设置中:
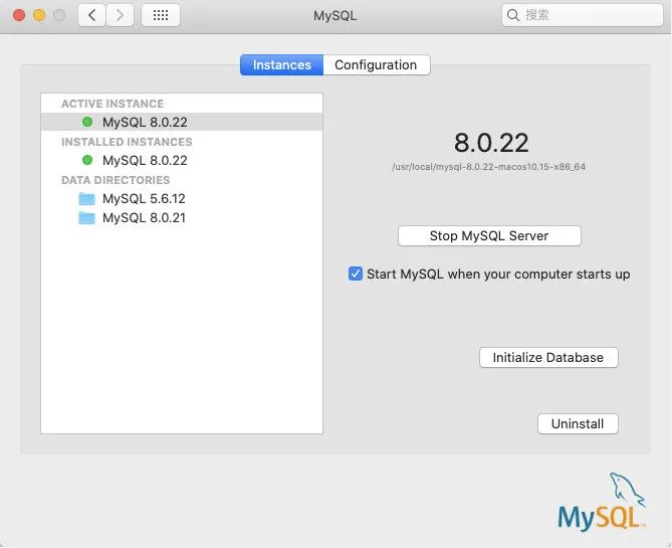
Mac 启动 MySQL
MySQL 连接/操作
打开终端,查看 MySQL 的安装:
- 这里会显示找不到命令;
mysql --version在 Windows 上配置环境变量:
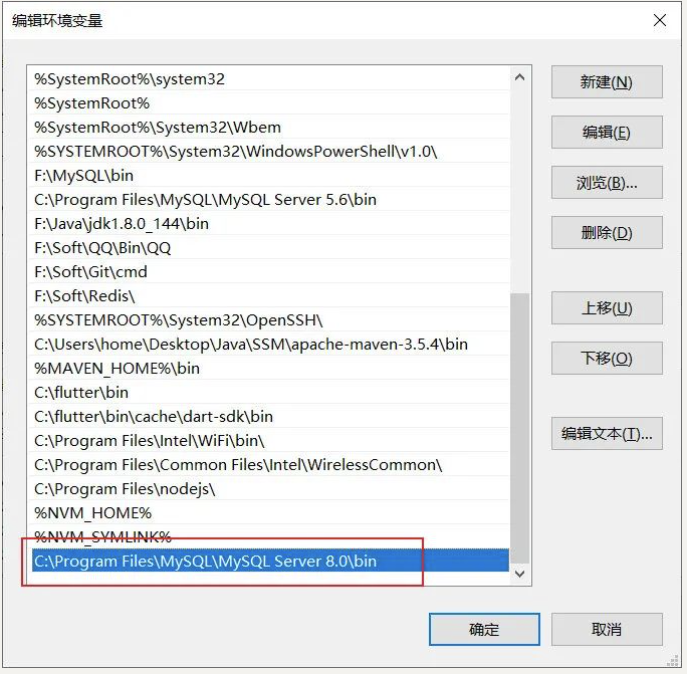
在 Mac 上配置环境变量:
手动执行下面的终端命令,将 MySQL 配置到环境变量中:
# 添加环境变量
export PATH=$PATH:/usr/local/mysql/bin
# 再次执行mysql版本
mysql --versionexport:shell 命令,用来设置环境变量。PATH:一个环境变量,包含了操作系统查找可执行文件的路径。$PATH:表示当前环境变量PATH的值。以冒号:分割。
终端连接数据库
我们如果想要操作数据,需要先和数据建立一个连接,最直接的方式就是通过终端来连接;
有两种方式来连接:
- 两种方式的区别在于输入密码是直接输入,还是另起一行以密文的形式输入;
# 方式一:
mysql -uroot -pCoderwhy888.
# 方式二:
mysql -uroot -p
Enter password: your password输入成功后,会进入到 mysql 的 REPL(交互式的编程环境):
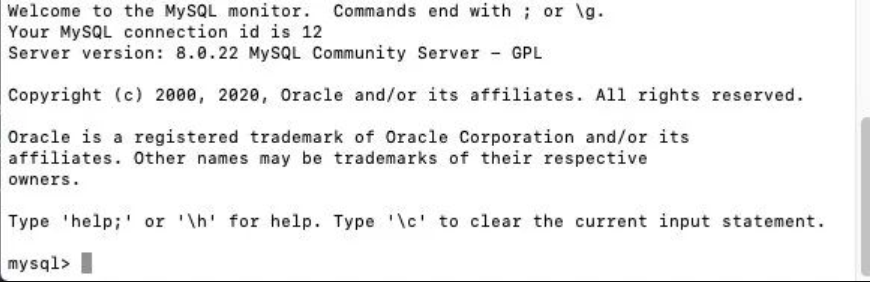
MySQL 的 REPL(交互式的编程环境):
我们可以直接在 REPL 中对数据库进行操作。
终端操作数据库
我们说过,一个数据库软件中,可以包含很多个数据库:
infomation_schema:信息数据库,其中包括 MySQL 在维护的其他数据库、表、列、访问权限等信息;performance_schema:性能数据库,记录着 MySQL Server 数据库引擎在运行过程中的一些资源消耗相关的信息;mysql:用于存储数据库管理者的用户信息、权限信息以及一些日志信息等;sys:相当于是一个简易版的 performance_schema,将数据汇总成更容易理解的形式;
注意:这里我只是在终端简单演练数据库,并没有详细讲解每一个命令,也没有完全按照 SQL 格式规范;
- 这些在后面会详细讲解的;
查看所有的数据库:
show databases;
创建数据库:
在终端直接创建一个属于自己的新的数据库 coderhub(一般情况下一个新的项目会对应一个新的数据库)。
create database coderhub;
查看当前正在使用的数据库:
select database();使用指定数据库:
使用我们创建的数据库 coderhub:
use coderhub;查看当前数据库中的所有表:
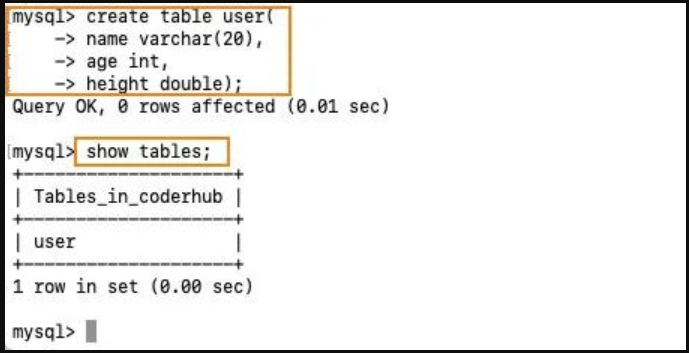
show tables;创建数据表:
在数据库中创建自己的表
create table user(
name varchar(20),
age int,
height double
);
插入数据:
在 user 表中插入自己的数据:
insert into user (name, age, height) values ('why', 18, 1.88);
insert into user (name, age, height) values ('kobe', 40, 1.98);
查询数据:
查看 user 表中所有的数据:
select * from user;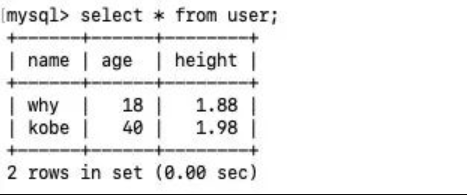
GUI 工具操作数据库
我们会发现在终端操作数据库有很多不方便的地方:
- 语句写出来没有高亮,并且不会有任何的提示;
- 复杂的语句分成多行,格式看起来并不美观,很容易出现错误;
- 终端中查看所有的数据库或者表非常的不直观和不方便;
- 等等...
所以在开发中,我们可以借助于一些 GUI 工具来帮助我们连接上数据库,之后直接在 GUI 工具中操作就会非常方便。
常见 MySQL 的 GUI 工具:
常见的 MySQL 的 GUI 工具有很多,这里推荐几款:
Navicat:个人最喜欢的一款工作,但是是收费的(有免费的试用时间,或者各显神通);SQLYog:一款免费的 SQL 工具;TablePlus:常用功能都可以使用,但是会多一些限制(比如只能开两个标签页);
这里我选择使用 Navicat。
1、连接数据库
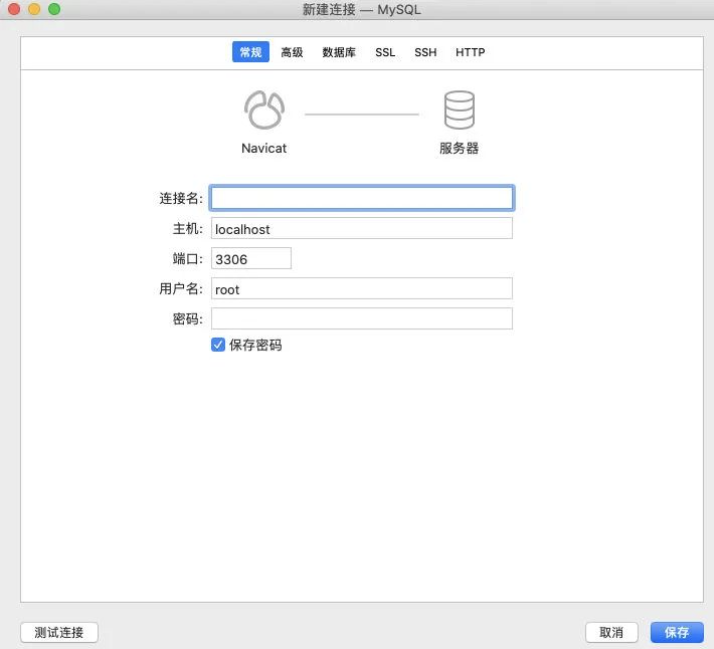
2、查看所有的数据库、表、表中的数据:
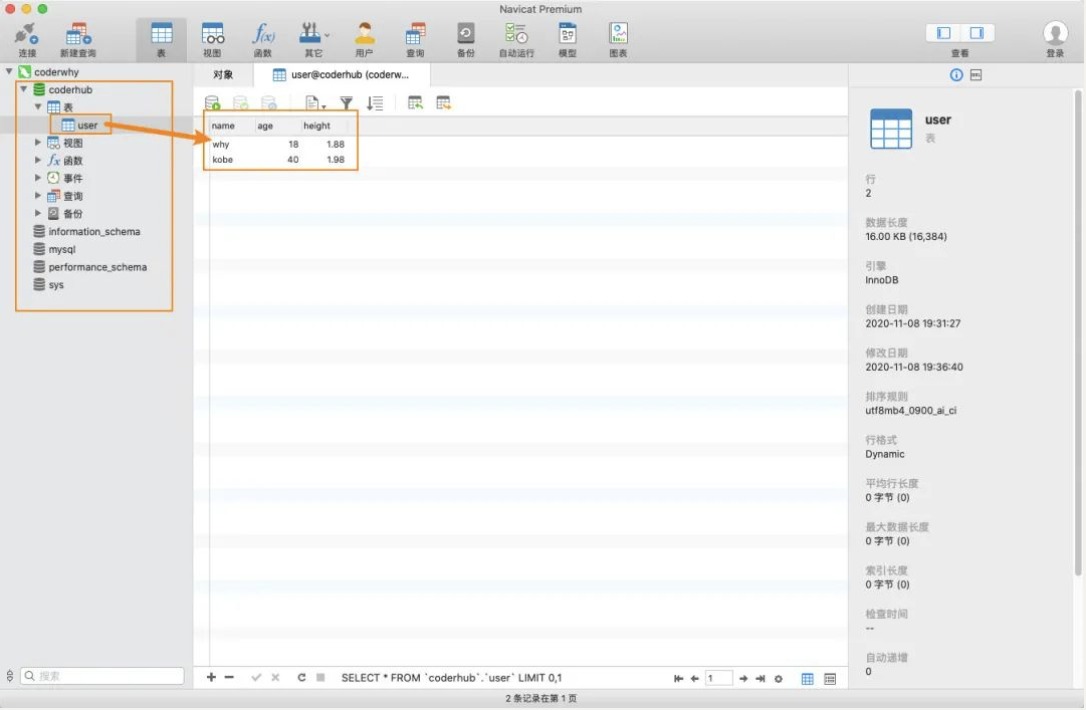
3、编写 SQL 语句,并且执行;
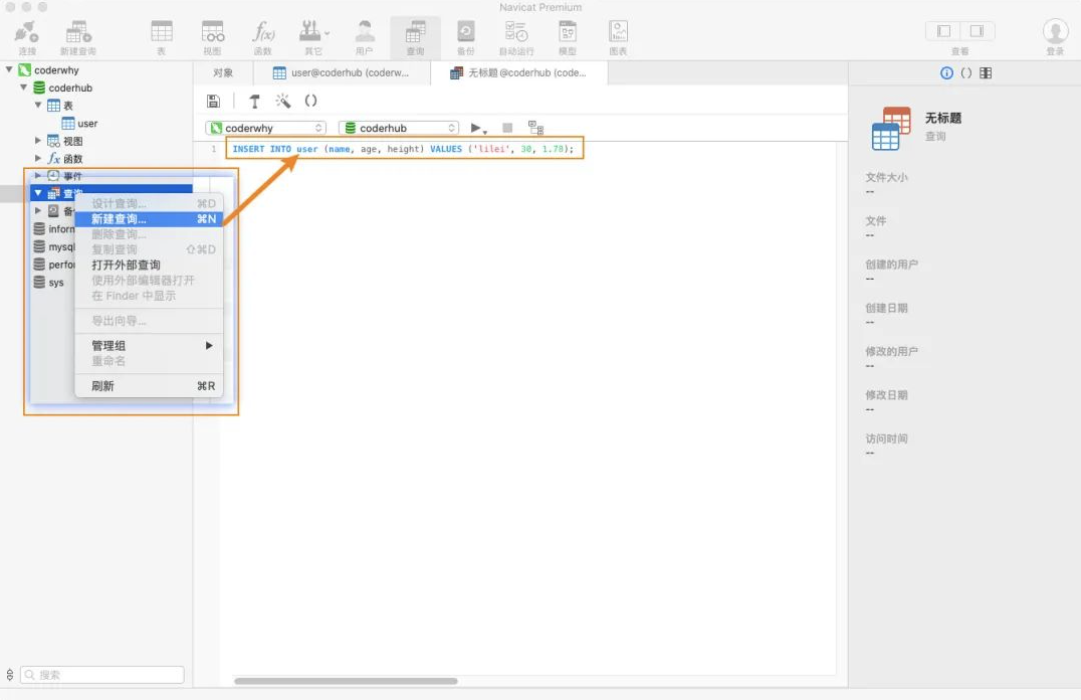
SQL 语句
认识 SQL 语句
我们希望操作数据库(特别是在程序中),就需要有和数据库沟通的语言,这个语言就是 SQL:
SQL是Structured Query Language,称之为结构化查询语言,简称 SQL;- 使用 SQL 编写出来的语句,就称之为
SQL 语句; - SQL 语句可以用于对数据库进行操作;
事实上,常见的关系型数据库 SQL 语句都是比较相似的,所以你学会了 MySQL 中的 SQL 语句,之后去操作比如 Oracle 或者其他关系型数据库,也是非常方便的。
SQL 语句的常用规范:
- 通常关键字是大写的,比如 CREATE、TABLE、SHOW 等等;
- 一条语句结束后,需要以
;结尾; - 如果遇到关键字作为表名或者字段名称,可以使用``包裹;
SQL 语句分类:
常见的 SQL 语句我们可以分成四类:
DDL(Data Definition Language,数据定义语言):可以通过 DDL 语句对数据库或者表进行:创建、删除、修改等操作;
DML(Data Manipulation Language,数据操作语言):可以通过 DML 语句对表中数据进行:添加、删除、修改等操作;
DQL(Data Query Language,数据查询语言):可以通过 DQL 从数据库中查询记录(重点);
DCL(Data Control Language,数据控制语言):对数据库、表格的权限进行相关访问控制操作;
接下来我们对他们进行一个个的学习和掌握。
DDL 语句
数据库的操作
查看当前的数据库:
# 查看所有的数据
SHOW DATABASES;
# 使用某一个数据
USE coderhub;
# 查看当前正在使用的数据库
SELECT DATABASE();创建数据库:
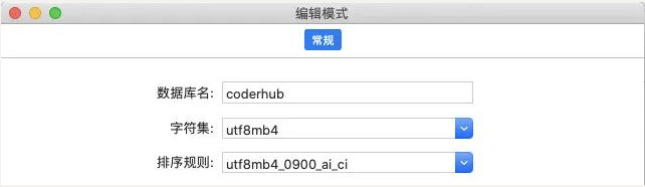
# 创建数据库
CREATE DATABASE bilibili;
CREATE DATABASE IF NOT EXISTS bilibili;
CREATE DATABASE
IF NOT EXISTS bilibili
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_0900_ai_ci;创建数据库时,可以设置字符串和字符排序(我们可以直接使用默认的):
- 字符集:
utf8mb4(默认,推荐)在我们需要插入 emoji 表情时要用到; - 排序规则:
utf8mb4_0900_ai_ci(默认,推荐) ai 表示不区分重音;ci 表示不区分大小写;
删除数据库:
# 删除数据库
DROP DATABASE bilibili;
DROP DATABASE IF EXISTS bilibili;修改数据库:
# 修改数据库的字符集和排序规则
ALTER DATABASE bilibili CHARACTER SET = utf8 COLLATE = utf8_unicode_ci;数据表的操作
查看数据表
# 查看所有的数据表
SHOW TABLES;
# 查看某一个表结构
DESC user;创建数据表
CREATE TABLE IF NOT EXISTS `users`(
name VARCHAR(20),
age INT,
height DOUBLE
);创建表细节
SQL 数据类型
我们知道不同的数据会划分为不同的数据类型,在数据库中也是一样:
MySQL 支持的数据类型有:数字类型,日期和时间类型,字符串(字符和字节)类型,空间类型和 JSON 数据类型。
数字类型:
MySQL 的数字类型有很多:
整数数字类型:
INTEGER,INT,SMALLINT,TINYINT,MEDIUMINT,BIGINT;
精确数字类型:
DECIMAL,NUMERIC(DECIMAL 是 NUMERIC 的实现形式);sql# 表示该列可以存储最多5位数字,其中包括2位小数,范围为 -999.99 到 999.99 salary DECIMAL(5,2)浮点数字类型:
FLOAT,DOUBLE- FLOAT 是 4 个字节,DOUBLE 是 8 个字节;
日期类型:
MySQL 的日期类型也很多:
YEAR:用于存储年份。- 显示格式:
YYYY - 范围:
1901到2155和0000。
- 显示格式:
DATE:用于具有日期部分但没有时间部分的值。- 显示格式:
YYYY-MM-DD - 范围:
'1000-01-01'到'9999-12-31'
- 显示格式:
DATETIME:用于包含日期和时间部分的值。- 显示格式:
YYYY-MM-DD hh:mm:ss - 范围:
1000-01-01 00:00:00到9999-12-31 23:59:59
- 显示格式:
TIMESTAMP:用于存储秒数时间戳。- 显示格式:
1759971003 - 范围:
'1970-01-01 00:00:01' UTC到'2038-01-19 03:14:07' UTC
- 显示格式:
小数秒精度:
DATETIME或TIMESTAMP值可以包括在高达微秒(6 位)精度的后小数秒一部分。- 比如 DATETIME 表示的范围可以是
'1000-01-01 00:00:00.000000'到'9999-12-31 23:59:59.999999';
- 比如 DATETIME 表示的范围可以是
字符串类型:
MySQL 的字符串类型表示方式如下:
CHAR:类型在创建表时为固定长度字符串,长度可以是 0 到 255 之间的任何值;- 在被查询时,会删除后面的空格;
VARCHAR:类型的值是可变长度字符串,长度可以指定为 0 到 65535 之间的值;- 在被查询时,不会删除后面的空格;
BINARY/VARBINARY: 类型用于存储二进制字符串,存储的是字节字符串;BLOB:用于存储大的二进制类型;TEXT:用于存储大的字符串类型;
表的约束
PRIMARY KEY:主键
一张表中,我们为了区分每一条记录的唯一性,必须有一个字段是永远不会重复,并且不会为空的,这个字段我们通常会将它设置为主键:
- 主键是表中唯一的索引;
- 并且必须是 NOT NULL 的,如果没有设置 NOT NULL,那么 MySQL 也会隐式的设置为 NOT NULL;
- 主键也可以是多列索引,
PRIMARY KEY(_key_part_, ...),我们一般称之为联合主键; - 建议:开发中主键字段应该是和业务无关的,尽量不要使用业务字段来作为主键;
UNIQUE:唯一
某些字段在开发中我们希望是唯一的,不会重复的,比如手机号码、身份证号码等,这个字段我们可以使用 UNIQUE 来约束:
- 使用 UNIQUE 约束的字段在表中必须是不重复的;
- 对于所有引擎,
UNIQUE索引 允许NULL包含的列具有多个值NULL。
NOT NULL:不能为空
某些字段我们要求用户必须插入值,不可以为空,这个时候我们可以使用 NOT NULL 来约束;
DEFAULT:默认值
某些字段我们希望在没有设置值时给予一个默认值,这个时候我们可以使用 DEFAULT 来完成;
AUTO_INCREMENT:自动递增
某些字段我们希望不设置值时可以进行递增,比如用户的 id,这个时候可以使用 AUTO_INCREMENT 来完成;
FOREIGN KEY () REFERENCES:外键约束
外键约束也是最常用的一种约束手段,我们再讲到多表关系时,再进行讲解;
DDL语句
创建表
# 创建表 - CREATE TABLE
CREATE TABLE IF NOT EXISTS `users`(
id INT PRIMARY KEY AUTO_INCREMENT, -- PRIMARY KEY, AUTO_INCREMENT
name VARCHAR(20) NOT NULL, -- NOT NULL
age INT DEFAULT 0, -- DEFAULT 0
telPhone VARCHAR(20) DEFAULT '' UNIQUE NOT NULL, -- DEFAULT '', UNIQUE, NOT NULL
createTime TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- DEFAULT CURRENT_TIMESTAMP
);删除数据表
# 删除表 - DROP TABLE
DROP TABLE `moment`;
DROP TABLE IF EXISTS `moment`;修改数据表
# 1.修改表名 - RENAME TO
ALTER TABLE `moments` RENAME TO `moment`;
# 2.添加一个新的列 - ADD
ALTER TABLE `moment` ADD `publishTime` DATETIME;
ALTER TABLE `moment` ADD `updateTime` DATETIME AFTER `publishTime`; -- 不支持 BEFORE
# 3.删除一列数据 DROP
ALTER TABLE `moment` DROP `updateTime`;
# 4.修改列的名称 CHANGE
ALTER TABLE `moment` CHANGE `publishTime` `publishDate` DATE;
# 5.修改列的数据类型 MODIFY
ALTER TABLE `moment` MODIFY `id` INT;不同数据库新增列语法对比:
| 数据库 | 正确语法 | 说明 |
|---|---|---|
| MySQL | ALTER TABLE table ADD column AFTER existing_column | 使用 AFTER |
| PostgreSQL | ALTER TABLE table ADD column BEFORE existing_column | 支持 BEFORE |
| SQLite | 不支持指定列位置 | 总是添加到末尾 |
| Oracle | 不支持指定列位置 | 需要重建表 |
DML 语句
新建一张商品表:
CREATE TABLE IF NOT EXISTS `products`(
`id` INT PRIMARY KEY AUTO_INCREMENT,
`title` VARCHAR(20),
`description` VARCHAR(200),
`price` DOUBLE,
`publishTime` DATETIME
);插入数据
# 插入数据 - INSERT INTO (...) VALUES (...)
INSERT INTO `products` (`title`,`description`, `price`, `publishTime`)
VALUES ('iPhone', 'iPhone12只要998', 998.88, '2020-10-10');
INSERT INTO `products` (`title`, `description`, `price`, `publishTime`)
VALUES ('huawei', 'iPhoneP40只要888', 888.88, '2020-11-11');删除数据
# 删除数据 - DELETE FROM ...
# 会删除表中所有的数据
DELETE FROM `products`;
# 会删除符合条件的数据
DELETE FROM `products` WHERE `title` = 'iPhone';修改数据
# 修改数据 - UPDATE ... SET ...
# 会修改表中所有的数据
UPDATE `products` SET `title` = 'iPhone12', `price` = 1299.88;
# 会修改符合条件的数据
UPDATE `products` SET `title` = 'iPhone12', `price` = 1299.88 WHERE `title` = 'iPhone';如果我们希望修改完数据后,直接可以显示最新的更新时间:
# 显示最新的更新时间
ALTER TABLE `products`
ADD `updateTime` TIMESTAMP
DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP;DQL 语句
SELECT 用于从一个或者多个表中检索选中的行(Record)。
SELECT select_expr [, select_expr]...
[FROM table_references]
[WHERE where_condition]
[ORDER BY expr [ASC | DESC]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[GROUP BY expr]
[HAVING where_condition]我们先准备一张表:
CREATE TABLE IF NOT EXISTS `products` (
id INT PRIMARY KEY AUTO_INCREMENT,
brand VARCHAR(20),
title VARCHAR(100) NOT NULL,
price DOUBLE NOT NULL,
score DECIMAL(2,1),
voteCnt INT,
url VARCHAR(100),
pid INT
);我们在其中插入一些数据:
const mysql = require('mysql2')
const connection = mysql.createConnection({
host: 'localhost',
port: 3306,
user: 'root',
password: 'Coderwhy888.',
database: 'coderhub'
})
const statement = `INSERT INTO products SET ?;`
const phoneJson = require('./phone.json')
for (let phone of phoneJson) {
connection.query(statement, phone)
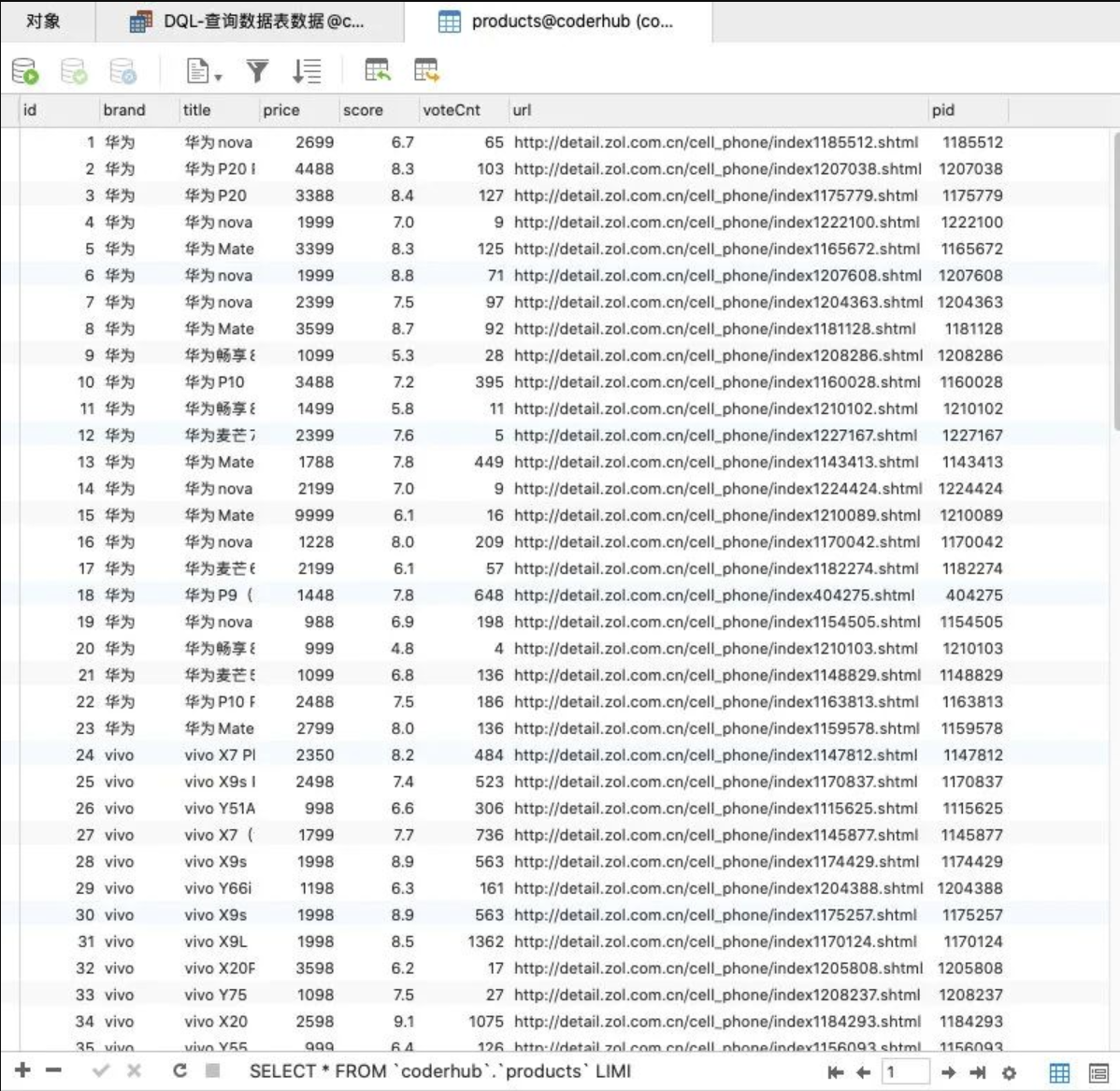
}
基本查询
查询所有字段:查询所有的数据并且显示所有的字段:
SELECT * FROM `products`;查询指定字段:查询 title、brand、price:
SELECT title, brand, price FROM `products`;设置字段别名:我们也可以给字段起别名:
- 别名一般在多张表或者给客户端返回对应的 key 时会使用到;
SELECT title as t, brand as b, price as p FROM `products`;注意: as 可以省略。
条件查询
在开发中,我们希望根据条件来筛选我们的数据,这个时候我们要使用条件查询:
- 条件查询会使用 WEHRE 查询子句;
WHERE 的比较运算符:
# 查询价格小于1000的手机
SELECT * FROM `products` WHERE price < 1000;
# 查询价格大于等于2000的手机
SELECT * FROM `products` WHERE price >= 2000;
# 价格等于3399的手机
SELECT * FROM `products` WHERE price = 3399;
# 价格不等于3399的手机
SELECT * FROM `products` WHERE price != 3399;
# 查询华为品牌的手机
SELECT * FROM `products` WHERE `brand` = '华为';WHERE 的逻辑运算符:
# AND 同时符合条件
# 查询品牌是华为,并且小于2000元的手机
SELECT * FROM `products` WHERE `brand` = '华为' and `price` < 2000;
SELECT * FROM `products` WHERE `brand` = '华为' && `price` < 2000;
# 查询1000到2000的手机(不包含1000和2000)
SELECT * FROM `products` WHERE price > 1000 and price < 2000;
# OR: 符合一个条件即可
# 查询所有的华为手机或者价格小于1000的手机
SELECT * FROM `products` WHERE brand = '华为' or price < 1000;
# BETWEEN AND 在某某区间(包含)之间
# 查询1000到2000的手机(包含1000和2000)
SELECT * FROM `products` WHERE price BETWEEN 1000 and 2000;
# IN () 存在于列举项中
# 查看多个结果中的一个
SELECT * FROM `products` WHERE brand in ('华为', '小米');WHERE 的模糊查询:
模糊查询使用LIKE关键字,结合两个特殊的符号:
%:表示匹配任意个的任意字符;_:表示匹配一个的任意字符;
# 查询所有以v开头的title
SELECT * FROM `products` WHERE title LIKE 'v%';
# 查询带M的title
SELECT * FROM `products` WHERE title LIKE '%M%';
# 查询带M的title必须是第三个字符
SELECT * FROM `products` WHERE title LIKE '__M%';查询排序
当我们查询到结果的时候,我们希望将结果按照某种方式进行排序,这个时候使用的是ORDER BY;
ORDER BY有两个常用的值:
ASC:升序排列;DESC:降序排列;
SELECT * FROM `products`
WHERE brand = '华为' or price < 1000
ORDER BY price ASC;分页偏移
当数据库中的数据非常多时,一次性查询到所有的结果进行显示是不太现实的:
- 在真实开发中,我们都会要求用户传入 offset、limit 或者 page 等字段;
- 它们的目的是让我们可以在数据库中进行分页查询;
- 它的用法有
[LIMIT [offset,] row_count | row_count OFFSET offset]
SELECT * FROM `products` LIMIT 30 OFFSET 0;
SELECT * FROM `products` LIMIT 30 OFFSET 30;
SELECT * FROM `products` LIMIT 30 OFFSET 60;
# 另外一种写法:offset, row_count
SELECT * FROM `products` LIMIT 90, 30;聚合函数@
聚合函数:表示对值集合进行操作的组(集合)函数。
聚合查询
我们这里学习最常用的一些聚合函数:
# 华为手机价格的平均值
SELECT AVG(price) FROM `products` WHERE brand = '华为';
# 计算所有手机的平均分
SELECT AVG(score) FROM `products`;
# 手机中最低和最高分数
SELECT MAX(score) FROM `products`;
SELECT MIN(score) FROM `products`;
# 计算总投票人数
SELECT SUM(voteCnt) FROM `products`;
# 计算所有条目的数量
SELECT COUNT(*) FROM `products`;
# 华为手机的个数
SELECT COUNT(*) FROM `products` WHERE brand = '华为';分组@
事实上聚合函数相当于默认将所有的数据分成了一组:
- 我们前面使用 avg 还是 max 等,都是将所有的结果看成一组来计算的;
- 那么如果我们希望划分多个组:比如华为、苹果、小米等手机分别的平均价格,应该怎么来做呢?
- 这个时候我们可以使用
GROUP BY;
GROUP BY通常和聚合函数一起使用:
- 表示我们先对数据进行分组,再对每一组数据,进行聚合函数的计算;
我们现在来提一个需求:
- 根据品牌进行分组;
- 计算各个品牌中商品的个数、平均价格、最高价格、最低价格、平均评分;
SELECT
brand,
COUNT(*) as count,
ROUND(AVG(price),2) as avgPrice,
MAX(price) as maxPrice,
MIN(price) as minPrice,
AVG(score) as avgScore
FROM `products`
GROUP BY brand;约束条件@
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句:可以让我们筛选分组后的各组数据。只有满足条件的分组会包含在结果集中。
对比 WHERE:
- where在group by前, having在group by 之后
- 聚合函数(avg、sum、max、min、count),不能作为条件放在where之后,但可以放在having之后
如果我们还希望筛选出平均价格在 4000 以下,并且平均分在 7 以上的品牌:
SELECT
brand,
COUNT(*) as count,
ROUND(AVG(price),2) as avgPrice,
MAX(price) as maxPrice,
MIN(price) as minPrice,
AVG(score) as avgScore
FROM `products`
GROUP BY brand
HAVING avgPrice < 4000 and avgScore > 7;外键约束@
创建多张表
假如我们的上面的商品表中,对应的品牌还需要包含其他的信息:
- 比如品牌的官网,品牌的世界排名,品牌的市值等等;
如果我们直接在商品中去体现品牌相关的信息,会存在一些问题:
- 一方面,products 表中应该表示的都是商品相关的数据,应该有另外一张表来表示 brand 的数据;
- 另一方面,多个商品使用的品牌是一致时,会存在大量的冗余数据;
所以,我们可以将所有的品牌数据,单独放到一张表中,创建一张品牌的表:
CREATE TABLE IF NOT EXISTS `brand`(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(20) UNIQUE NOT NULL,
website VARCHAR(100),
worldRank INT
);插入模拟的数据:
- 这里我是刻意有一些商品数据的品牌是没有添加的(锤子科技);
- 并且也可以添加了一些不存在的手机品牌(京东、Google);
INSERT INTO `brand` (name, website, worldRank) VALUES ('华为', 'www.huawei.com', 1);
INSERT INTO `brand` (name, website, worldRank) VALUES ('小米', 'www.mi.com', 10);
INSERT INTO `brand` (name, website, worldRank) VALUES ('苹果', 'www.apple.com', 5);
INSERT INTO `brand` (name, website, worldRank) VALUES ('oppo', 'www.oppo.com', 15);
INSERT INTO `brand` (name, website, worldRank) VALUES ('京东', 'www.jd.com', 3);
INSERT INTO `brand` (name, website, worldRank) VALUES ('Google', 'www.google.com', 8);创建外键
我们先给products添加一个brand_id字段:
将两张表联系起来,我们可以将products中的brand_id关联到brand中的id:
如果是创建表添加外键约束:
sqlFOREIGN KEY (brand_id) REFERENCES brand(id)如果是表已经创建好,额外添加外键:
sqlALTER TABLE `products` ADD `brand_id` INT; ALTER TABLE `products` ADD FOREIGN KEY (brand_id) REFERENCES brand(id);
现在我们可以将products中的brand_id关联到brand中的id的值:
UPDATE `products` SET `brand_id` = 1 WHERE `brand` = '华为';
UPDATE `products` SET `brand_id` = 4 WHERE `brand` = 'OPPO';
UPDATE `products` SET `brand_id` = 3 WHERE `brand` = '苹果';
UPDATE `products` SET `brand_id` = 2 WHERE `brand` = '小米';删除和更新
我们来思考一个问题:
- 如果
products中引用的外键被更新了或者删除了,这个时候会出现什么情况呢?
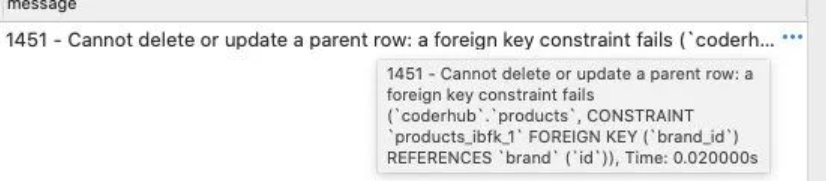
我们来进行一个更新操作:比如将华为的 id 更新为 100
UPDATE `brand` SET id = 100 WHERE id = 1;这个时候执行代码是报错的:
不可以更新和删除,因为有一个外键引用
如果我希望可以更新呢?我们可以给更新时设置几个值:
RESTRICT(默认属性):当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话会报错的,不允许更新或删除;NO ACTION:和 RESTRICT 是一致的,是在 SQL 标准中定义的;CASCADE:级联,当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话:- 更新:那么会更新对应的记录;
- 删除:那么关联的记录会被一起删除掉;
SET NULL:当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话,将对应的值设置为 NULL;
如果修改外键的更新时的动作呢?
第一步:查看表结构:
# 执行命令
SHOW CREATE TABLE `products`;
# 结果如下:
CREATE TABLE `products` (
`id` int NOT NULL AUTO_INCREMENT,
`brand` varchar(20) DEFAULT NULL,
`title` varchar(100) NOT NULL,
`price` double NOT NULL,
`score` decimal(2,1) DEFAULT NULL,
`voteCnt` int DEFAULT NULL,
`url` varchar(100) DEFAULT NULL,
`pid` int DEFAULT NULL,
`brand_id` int DEFAULT NULL,
PRIMARY KEY (`id`), KEY `brand_id` (`brand_id`),
CONSTRAINT `products_ibfk_1` FOREIGN KEY (`brand_id`) REFERENCES `brand` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=109 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci这个时候,我们可以知道外键的名称是products_ibfk_1。
第二步:删除之前的外键
ALTER TABLE `products`
DROP FOREIGN KEY products_ibfk_1;第三步:添加新的外键,并且设置新的 action
ALTER TABLE `products`
ADD FOREIGN KEY (brand_id) REFERENCES brand(id)
ON UPDATE CASCADE
ON DELETE CASCADE;多表查询@
多表查询
如果我们希望查询到产品的同时,显示对应的品牌相关的信息,因为数据是存放在两张表中,所以这个时候就需要进行多表查询。
方式一:笛卡尔乘积
如果我们直接通过查询语句希望在多张表中查询到数据,这个时候是什么效果呢?
SELECT * FROM `products`, `brand`;查询结果
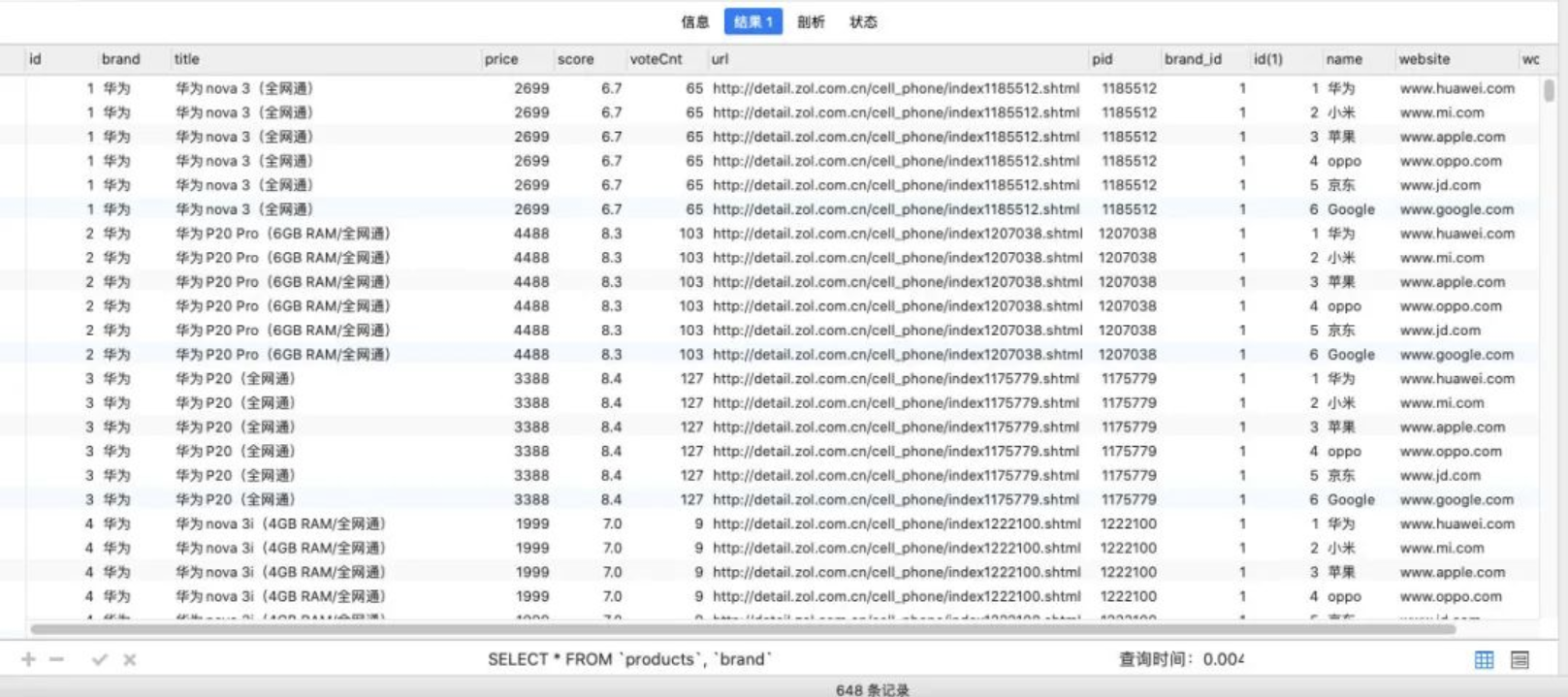
我们会发现一共有 648 条数据,这个数据量是如何得到的呢?
- 第一张表的 108 条 * 第二张表的 6 条数据;
- 也就是说第一张表中每一个条数据,都会和第二张表中的每一条数据结合一次;
- 这个结果我们称之为 笛卡尔乘积,也称之为直积,表示为
X*Y;
方式二:使用 WHERE 筛选
但是事实上很多的数据是没有意义的,比如华为和苹果、小米的品牌结合起来的数据就是没有意义的,我们可不可以进行筛选呢?
- 使用 where 来进行筛选;
- 这个表示查询到笛卡尔乘积后的结果中,符合
products.brand_id = brand.id条件的数据过滤出来;
SELECT * FROM `products`, `brand`
WHERE `products`.brand_id = `brand`.id;方式三:SQL JOIN 操作:
事实上我们想要的效果并不是这样的,而且表中的某些特定的数据,这个时候我们可以使用 SQL JOIN 操作:
- 左连接
- 右连接
- 内连接
- 全连接
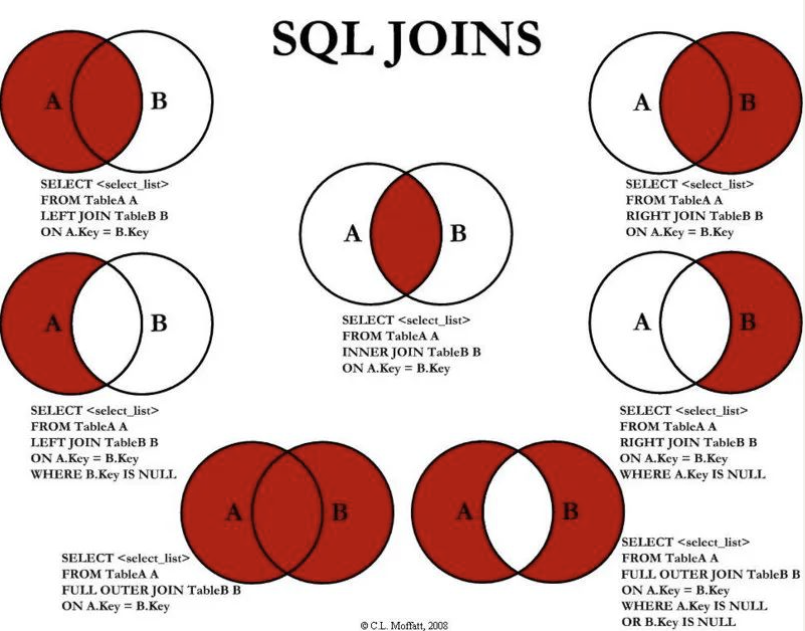
左连接
如果我们希望获取到的是左边所有的数据(以左表为主):
- 这个时候就表示无论左边的表是否有对应的
brand_id的值对应右边表的id,左边的数据都会被查询出来; - 这个也是开发中使用最多的情况,它的完整写法是
LEFT [OUTER] JOIN,但是 OUTER 可以省略的;
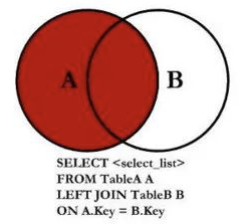
SELECT * FROM `products`
LEFT JOIN `brand` ON `products`.brand_id = `brand`.id;如果我们查询的是左连接部分中,和右表无关的数据:
- 也非常简单,只需要加上一个条件即可:B 表中的数据为空
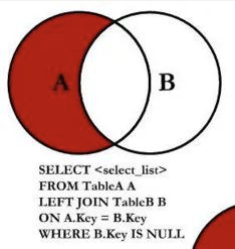
SELECT * FROM `products`
LEFT JOIN `brand` ON `products`.brand_id = `brand`.id
WHERE brand.id IS NULL;右连接
如果我们希望获取到的是右边的所有数据(以右表为主):
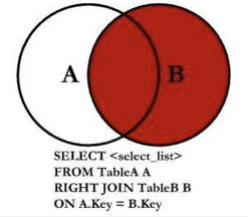
- 这个时候就表示无论左边的表中的
brand_id是否有和右边表中的id对应,右边的数据都会被查询出来; - 右连接在开发中没有左连接常用,它的完整写法是
RIGHT [OUTER] JOIN,但是 OUTER 可以省略的;
SELECT * FROM `products`
RIGHT JOIN `brand` ON `products`.brand_id = `brand`.id;如果我们查询的是右连接部分中,和左表无关的数据:
- 也非常简单,只需要加上一个条件即可:A 表中的数据为空;

SELECT * FROM `products`
RIGHT JOIN `brand` ON `products`.brand_id = `brand`.id
WHERE products.id IS NULL;内连接
事实上内连接是表示左边的表和右边的表都有对应的数据关联:
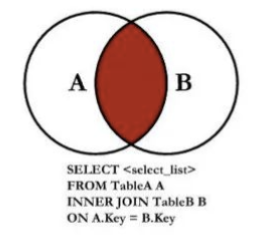
SELECT * FROM `products`
INNER JOIN `brand` ON `products`.brand_id = `brand`.id;对比 WHERE 筛选:
我们会发现它和之前的下面写法是一样的效果:
SELECT * FROM `products`, `brand` WHERE `products`.brand_id = `brand`.id;但是他们代表的含义并不相同:
- SQL 语句一:内连接,代表的是在两张表连接时就会约束数据之间的关系,来决定之后查询的结果;
- SQL 语句二:where 条件,代表的是先计算出笛卡尔乘积,在笛卡尔乘积的数据基础之上进行 where 条件的筛选;
内连接在开发中偶尔也会常见使用,看自己的场景。
内连接有其他的写法:[CROSS] [INNER] JOIN,CROSE 和 INNER 可以省略,可以直接写成 JOIN;
全连接
SQL 规范中全连接是使用 FULL JOIN,但是 MySQL 中并没有对它的支持,我们需要使用 UNION 来实现:
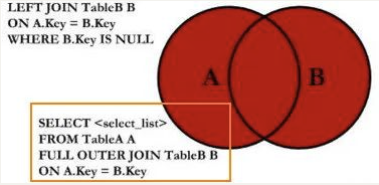
# 左连接 UNION 右连接
(SELECT * FROM `products` LEFT JOIN `brand` ON `products`.brand_id = `brand`.id)
UNION
(SELECT * FROM `products` RIGHT JOIN `brand` ON `products`.brand_id = `brand`.id);如果我们希望查询的是下面的结果:
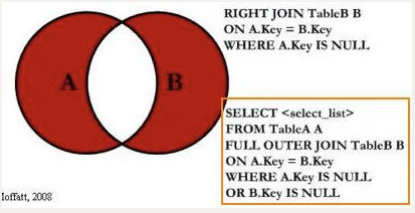
(SELECT * FROM `products` LEFT JOIN `brand` ON `products`.brand_id = `brand`.id WHERE `brand`.id IS NULL)
UNION
(SELECT * FROM `products` RIGHT JOIN `brand` ON `products`.brand_id = `brand`.id WHERE `products`.id IS NULL);多对多关系@
准备多张表
在开发中我们还会遇到多对多的关系:
- 比如学生可以选择多门课程,一个课程可以被多个学生选择;
- 这种情况我们应该在开发中如何处理呢?
这个时候我们通常是会建三张表来建立它们之间的关系的:
# 创建学生表
CREATE TABLE IF NOT EXISTS `students`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
age INT
);
# 创建课程表
CREATE TABLE IF NOT EXISTS `courses`(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL UNIQUE,
price DOUBLE NOT NULL
);我们在两张表中插入一些数据:
INSERT INTO `students` (name, age) VALUES('why', 18);
INSERT INTO `students` (name, age) VALUES('tom', 22);
INSERT INTO `students` (name, age) VALUES('lilei', 25);
INSERT INTO `students` (name, age) VALUES('lucy', 16);
INSERT INTO `students` (name, age) VALUES('lily', 20);
INSERT INTO `courses` (name, price) VALUES ('英语', 100);
INSERT INTO `courses` (name, price) VALUES ('语文', 666);
INSERT INTO `courses` (name, price) VALUES ('数学', 888);
INSERT INTO `courses` (name, price) VALUES ('历史', 80);创建关系表
我们需要一个关系表来记录两张表中的数据关系:
# 创建关系表
CREATE TABLE IF NOT EXISTS `students_select_courses`(
id INT PRIMARY KEY AUTO_INCREMENT,
student_id INT NOT NULL,
course_id INT NOT NULL,
FOREIGN KEY (student_id) REFERENCES students(id) ON UPDATE CASCADE ON DELETE CASCADE,
FOREIGN KEY (course_id) REFERENCES courses(id) ON UPDATE CASCADE ON DELETE CASCADE
);我们插入一些数据:
# why 选修了 英文和数学
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (1, 1);
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (1, 3);
# lilei选修了 语文和数学和历史
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (3, 2);
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (3, 3);
INSERT INTO `students_select_courses` (student_id, course_id) VALUES (3, 4);多表数据查询
查询多条数据:
# 查询所有有选课的学生的选课情况(内连接)
SELECT stu.id studentId, stu.name studentName, cs.id courseId, cs.name courseName, cs.price coursePrice
FROM `students` stu
JOIN `students_select_courses` ssc ON stu.id = ssc.student_id
JOIN `courses` cs ON ssc.course_id = cs.id;
# 查询所有学生的选课情况(左连接)
SELECT stu.id studentId, stu.name studentName, cs.id courseId, cs.name courseName, cs.price coursePrice
FROM `students` stu
LEFT JOIN `students_select_courses` ssc ON stu.id = ssc.student_id
LEFT JOIN `courses` cs ON ssc.course_id = cs.id;查询单个学生的课程:
# why同学选择了哪些课程
SELECT stu.id studentId, stu.name studentName, cs.id courseId, cs.name courseName, cs.price coursePrice
FROM `students` stu
JOIN `students_select_courses` ssc ON stu.id = ssc.student_id
JOIN `courses` cs ON ssc.course_id = cs.id
WHERE stu.id = 1;
# lily同学选择了哪些课程
SELECT stu.id studentId, stu.name studentName, cs.id courseId, cs.name courseName, cs.price coursePrice
FROM `students` stu
LEFT JOIN `students_select_courses` ssc ON stu.id = ssc.student_id
LEFT JOIN `courses` cs ON ssc.course_id = cs.id
WHERE stu.id = 5;查询哪些学生没有选择和哪些课程没有被选择:
# 哪些学生是没有选过课
SELECT stu.id studentId, stu.name studentName, cs.id courseId, cs.name courseName, cs.price coursePrice
FROM `students` stu
LEFT JOIN `students_select_courses` ssc ON stu.id = ssc.student_id
LEFT JOIN `courses` cs ON ssc.course_id = cs.id
WHERE cs.id IS NULL;
# 查询哪些课程没有被学生选择
SELECT stu.id studentId, stu.name studentName, cs.id courseId, cs.name courseName, cs.price coursePrice
FROM `students` stu
RIGHT JOIN `students_select_courses` ssc ON stu.id = ssc.student_id -- 右连接
RIGHT JOIN `courses` cs ON ssc.course_id = cs.id -- 右连接
WHERE stu.id IS NULL;对象和数组@
一对多-对象
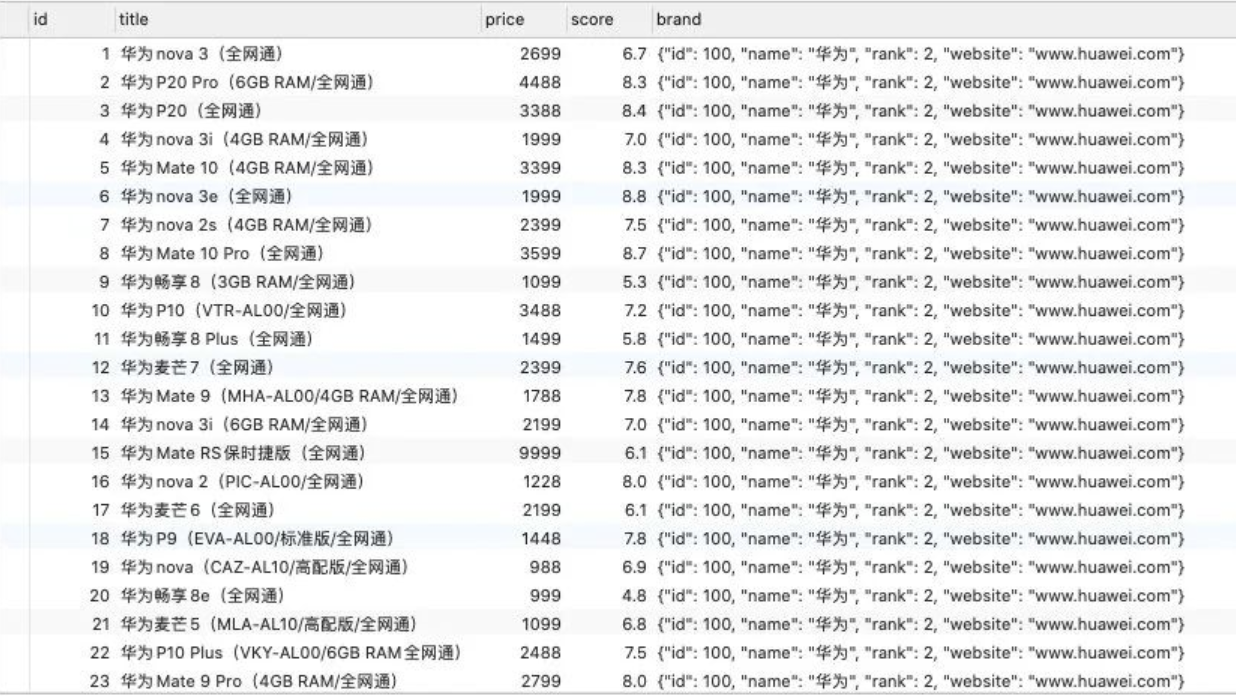
前面我们学习的查询语句,查询到的结果通常是一张表,比如查询手机+品牌信息:
SELECT * FROM products
LEFT JOIN brand ON products.brand_id = brand.id;查询结果

但是在真实开发中,实际上红色圈起来的部分应该放入到一个对象中,那么我们可以使用下面的查询方式:
- 这个时候我们要用
JSON_OBJECT;
SELECT
products.id as id,
products.title as title,
products.price as price,
products.score as score,
JSON_OBJECT(
'id', brand.id,
'name', brand.name,
'rank', brand.phoneRank,
'website', brand.website
) as brand
FROM products
LEFT JOIN brand ON products.brand_id = brand.id;查询结果
多对多-数组
在多对多关系中,我们希望查询到的是一个数组:
- 比如一个学生的多门课程信息,应该是放到一个数组中的;
- 数组中存放的是课程信息的一个个对象;
- 这个时候我们要
JSON_ARRAYAGG和JSON_OBJECT结合来使用;
SELECT
stu.id,
stu.name,
stu.age,
JSON_ARRAYAGG(JSON_OBJECT('id', cs.id, 'name', cs.name)) as courses
FROM students stu
LEFT JOIN students_select_courses ssc ON stu.id = ssc.student_id
LEFT JOIN courses cs ON ssc.course_id = cs.id
GROUP BY stu.id;查询结果
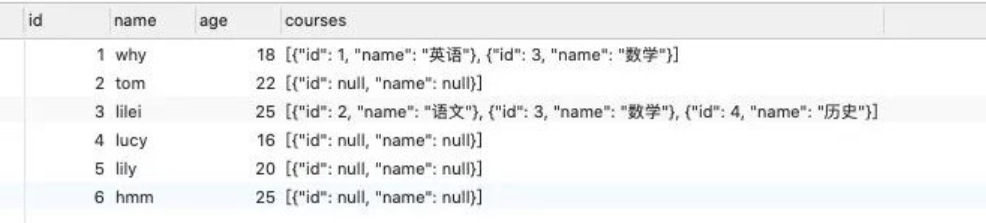
Node 操作 MySQL
mysql2@
认识 mysql2
前面我们所有的操作都是在 GUI 工具中,通过执行 SQL 语句来获取结果的,那真实开发中肯定是通过代码来完成所有的操作的。
那么如何可以在 Node 的代码中执行 SQL 语句来,这里我们可以借助于两个库:
- mysql:最早的 Node 连接 MySQL 的数据库驱动;
- mysql2:在 mysql 的基础之上,进行了很多的优化、改进;
mysql2 优势:
目前相对来说,我更偏向于使用 mysql2,mysql2 兼容 mysql 的 API,并且提供了一些附加功能
更快/更好的性能
Prepared Statement(预编译语句):
- 提高性能:将创建的语句模块发送给 MySQL,然后 MySQL 编译(解析、优化、转换)语句模块,并且存储它但是不执行,之后我们在真正执行时会给
?提供实际的参数才会执行;就算多次执行,也只会编译一次,所以性能是更高的; - 防止 SQL 注入:之后传入的值不会像模块引擎那样就编译,那么一些 SQL 注入的内容不会被执行;
or 1 = 1不会被执行;
- 提高性能:将创建的语句模块发送给 MySQL,然后 MySQL 编译(解析、优化、转换)语句模块,并且存储它但是不执行,之后我们在真正执行时会给
支持 Promise:所以我们可以使用 async 和 await 语法
等等....
所以后续的学习中我会选择 mysql2 在 node 中操作数据。
安装:
npm install mysql2基本使用
mysql2 的使用过程如下:
- 第一步:创建连接(通过 createConnection),并且获取连接对象;
- 第二步:执行 SQL 语句即可(通过 query);
// 1. 创建连接
const mysql = require('mysql2')
const connection = mysql.createConnection({
host: 'localhost',
database: 'coderhub',
user: 'root',
password: 'Coderwhy888.'
})
// 2. 执行SQL语句
connection.query('SELECT title, price FROM products WHERE price > 9000;', (err, results, fields) => {
console.log(err)
console.log('----------')
console.log(results)
console.log('----------')
console.log(fields)
})查询结果:
通常我们的连接建立之后是不会轻易断开的,因为我们需要这个连接持续帮助我们查询客户端过来的请求。
但是如果我们确实希望断开连接,可以使用 end 方法:
connection.end()预编译语句
Prepared Statement(预编译语句):
- 提高性能:
- 将创建的语句模块发送给 MySQL;
- 然后 MySQL 编译(解析、优化、转换)语句模块,并且存储它但是不执行;
- 之后我们在真正执行时会给
?提供实际的参数才会执行; - 就算多次执行,也只会编译一次,所以性能是更高的;
- 防止 SQL 注入:之后传入的值不会像模块引擎那样就编译,那么一些 SQL 注入的内容不会被执行;
or 1 = 1不会被执行;
const statement = 'SELECT * FROM products WHERE price > ? and brand = ?;'
connection.execute(statement, [1000, '华为'], (err, results) => {
console.log(results)
})强调:如果再次执行该语句,它将会从 LRU(Least Recently Used) Cache 中获取获取,省略了编译 statement 的时间来提高性能。
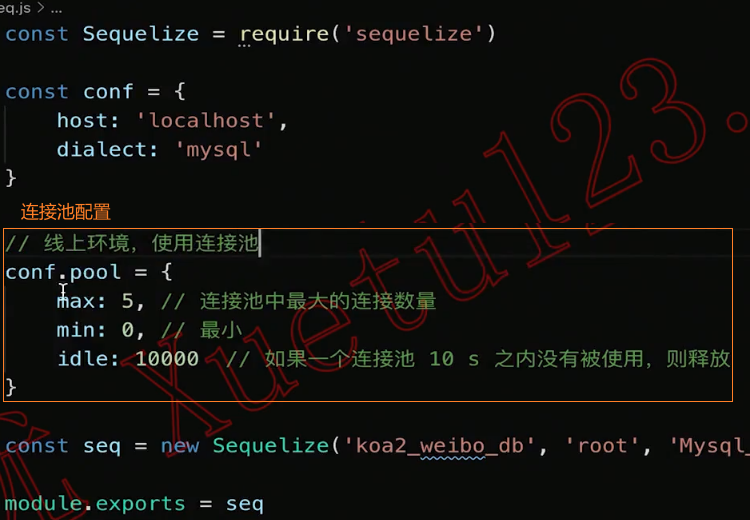
连接池
前面我们是创建了一个连接(connection),但是如果我们有多个请求的话,该连接很有可能正在被占用,那么我们是否需要每次一个请求都去创建一个新的连接呢?
- 事实上,mysql2 给我们提供了
连接池(Connection Pools); - 连接池可以在需要的时候自动创建连接,并且创建的连接不会被销毁,会放到连接池中,后续可以继续使用;
- 我们可以在创建连接池的时候设置
connectionLimit,也就是最大创建个数;
const mysql = require('mysql2')
const pool = mysql.createPool({
host: 'localhost',
database: 'coderhub',
user: 'root',
password: 'Coderwhy888.',
connectionLimit: 10
})
const statement = 'SELECT * FROM products WHERE price > ? and brand = ?;'
pool.execute(statement, [1000, '华为'], (err, results) => {
console.log(results)
})为什么 Node 执行 JavaScript 时单线程的,还需要连接池呢?
- 这是因为 Node 中操作数据库,本质上是通过 Libuv 进行了的数据库操作;
- 而在 libuv 中是可以有多个线程的,多个线程也是可以同时去建立连接来操作数据库的;
Promise 写法
目前在 JavaScript 开发中我们更习惯 Promise 和 await、async 的方式,mysql2 同样是支持的:
const mysql = require('mysql2')
const pool = mysql.createPool({
host: 'localhost',
database: 'coderhub',
user: 'root',
password: 'Coderwhy888.',
connectionLimit: 5
})
const statement = 'SELECT * FROM products WHERE price > ? and brand = ?;'
pool
.promise()
.execute(statement, [1000, '华为'])
.then(([results]) => { // 此处需要解构出 results
console.log(results)
})
.catch(err => {
console.log(err)
})sequelize@
API-sequelize
- 连接数据库
- new Sequelize():
(),创建 Sequelize 类实例对象 - seq.authenticate():
(),测试连接是否正常 - 创建映射关系
- Model.init():
(),创建表模型映射关系 - 增删改查
- Model.findOne():
(),查询一条表数据 - Model.findAll():
(),查询多条表数据 - Model.findAndCountAll():
(),查询多条表数据并计总数 - Model.create():
(),插入表数据 - Model.update():
(),更新表数据 - Model.destroy():
(),删除表数据 - 表关系
- Model.belongsTo():
(),表属于另一个表(一对多) - Model.hasMany():
(),表拥有另一个表(一对多) - Model.belongsToMany():
(),表属于众多表之一(多对多)
认识 ORM
对象关系映射(Object Relational Mapping,ORM,O/RM,O/R mapping),是一种程序设计的方案:
- 从效果上来讲,它提供了一个可在编程语言中,使用虚拟对象数据库的效果;
- 比如在 Java 开发中经常使用的 ORM 包括:Hibernate、MyBatis;
Node 当中的 ORM 我们通常使用的是 Sequelize;
Sequelize:是用于 Postgres,MySQL,MariaDB,SQLite 和 Microsoft SQL Server 的基于 Node.js 的 ORM;- 它支持非常多的功能;
安装:
如果我们希望将 Sequelize 和 MySQL 一起使用,那么我们需要先安装两个东西:
- mysql2:sequelize 在操作 mysql 时使用的是 mysql2;
- sequelize:使用它来让对象映射到表中;
npm install sequelize mysql2基本使用
连接数据库
- 第一步:创建一个 Sequelize 的对象,并且指定数据库、用户名、密码、数据库类型、主机地址等;
- 第二步:测试连接是否成功;
const { Sequelize, DataTypes, Model, Op } = require('sequelize')
// 1. 创建 sequelize 对象
const sequelize = new Sequelize('coderhub', 'root', 'Coderwhy888.', {
host: 'localhost',
dialect: 'mysql'
})
// 2. 测试连接
sequelize
.authenticate()
.then(() => {
console.log('sequelize连接成功~')
})
.catch((err) => {
console.log('sequlize连接失败~', err)
})映射关系表
方式一:Model.init()(推荐)
class Student extends Model {}
Student.init(
{
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true
},
name: {
type: DataTypes.STRING,
allowNull: false
},
age: DataTypes.INTEGER
},
{
tableName: 'students',
sequelize,
createdAt: false,
updatedAt: false
}
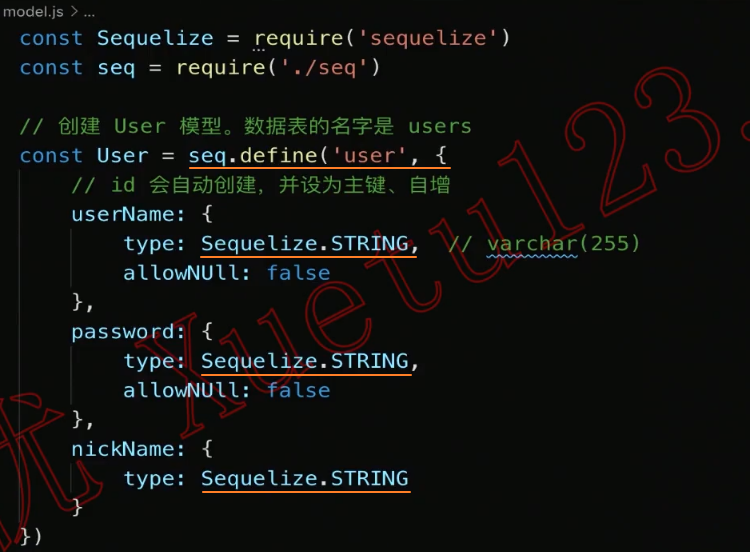
)方式二:Moddel.define()(旧版)
1、创建表映射模型
- 默认自动创建 createdAt 和 updatedAt
2、测试同步到数据库
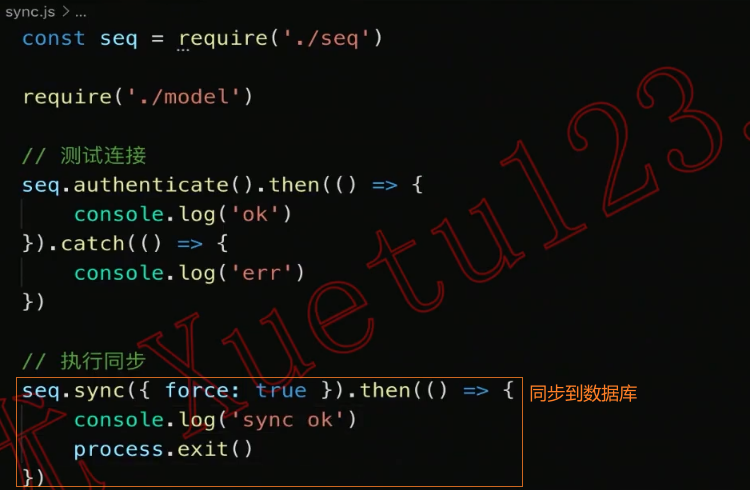
增删改查
async function queryStudent() {
// 1.查询所有的学生
const result1 = await Student.findAll({})
console.log(result1)
// 2.查询年龄大于等于20岁的学生
const result2 = await Student.findAll({
// WHERE 条件
where: {
age: {
[Op.gte]: 20
}
}
})
console.log(result2)
// 3.插入用户
const result3 = await Student.create({ name: 'hmm', age: 22 })
console.log(result3)
// 4.更新用户
const result4 = await Student.update({ age: 25 }, { where: { id: 6 } })
console.log(result4)
// 5.删除用户
const result5 = await Student.destroy({where: { id: 2 }})
console.log(result5)
}
queryStudent()排序查询:
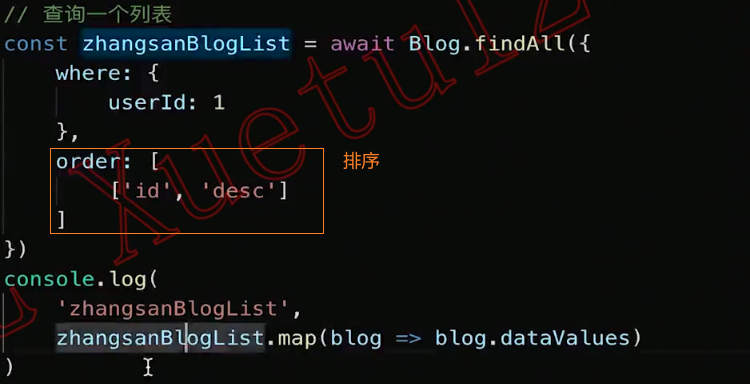
分页查询:
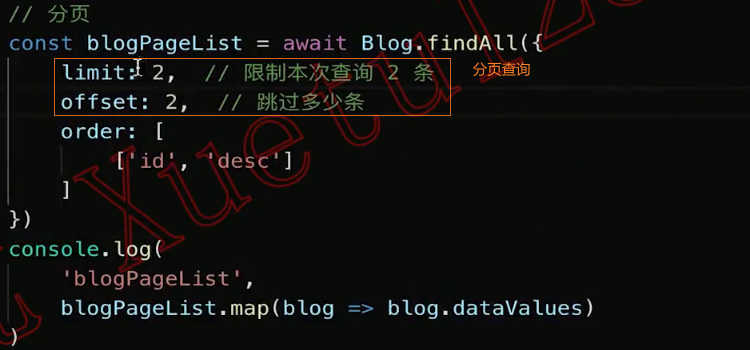
查询总数:
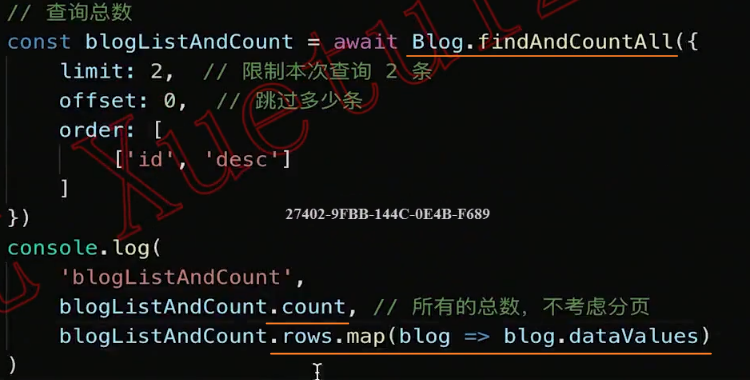
查询参数选项:
- where:
object,条件语句 - attributes:
array,显示指定的列 - order:
二维数组,排序 - :``,
- :``,
一对多关系
1、创建 Brand 表映射
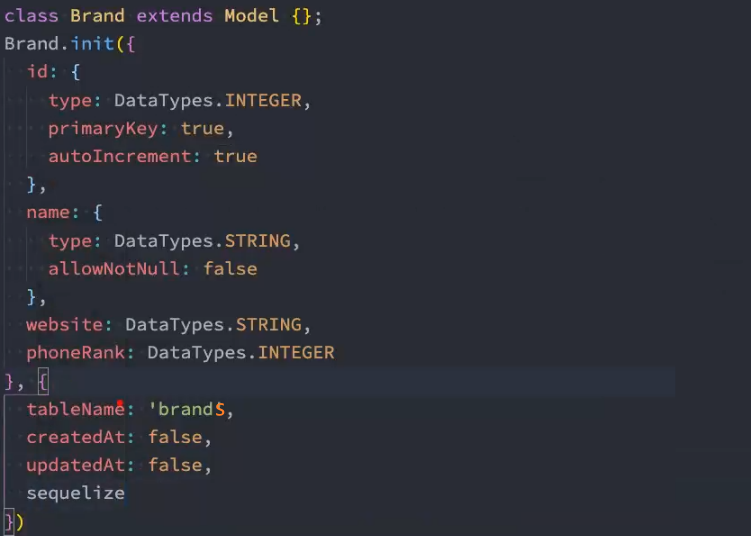
2、建立 Brand 和 Product 表之间的外键约束
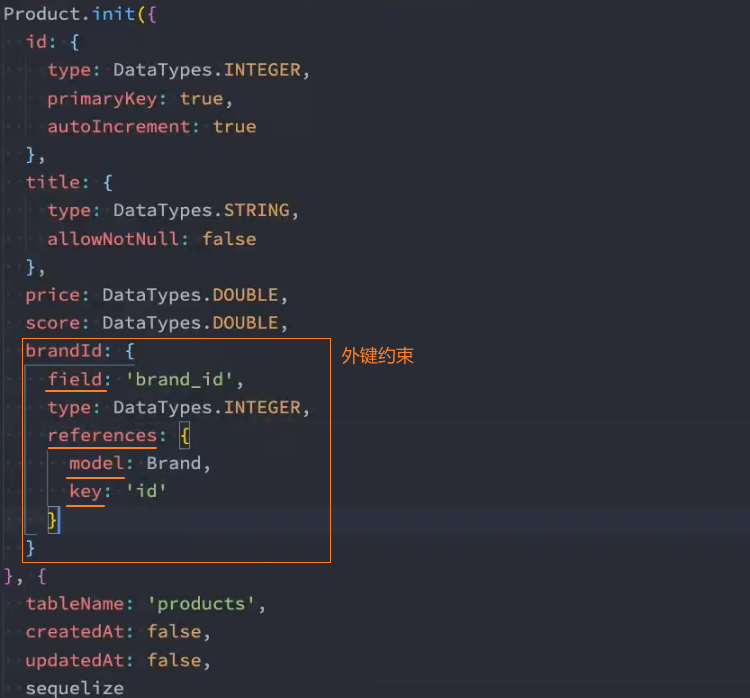
3、将2张表联系在一起
写法一:
belongsTo()
写法二:
hasMany()
4、多表查询
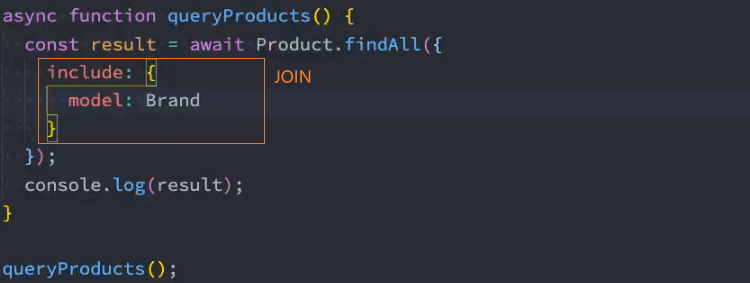
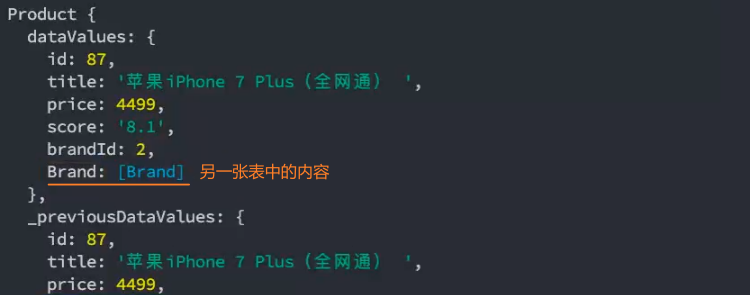
多对多关系
第一步:连接数据库
const { Sequelize, DataTypes, Model, Op } = require('sequelize')
const sequelize = new Sequelize('coderhub', 'root', 'Coderwhy888.', {
host: 'localhost',
dialect: 'mysql'
})第二步:创建映射关系
// student 表
class Student extends Model {}
Student.init(
{
id: { type: DataTypes.INTEGER, primaryKey: true, autoIncrement: true },
name: { type: DataTypes.STRING, allowNull: false },
age: DataTypes.INTEGER
},
{ sequelize, createdAt: false, updatedAt: false }
)// course 表
class Course extends Model {}
Course.init(
{
id: { type: DataTypes.INTEGER, primaryKey: true, autoIncrement: true },
name: { type: DataTypes.STRING(20), allowNull: false },
price: { type: DataTypes.DOUBLE, allowNull: false }
},
{ sequelize, createdAt: false, updatedAt: false }
)// students_select_courses 表
class StudentCourse extends Model {}
StudentCourse.init(
{
id: { type: DataTypes.INTEGER, primaryKey: true, autoIncrement: true },
studentId: {
type: DataTypes.INTEGER,
references: { model: Student, key: 'id' },
field: 'student_id'
},
courseId: {
type: DataTypes.INTEGER,
references: { model: Course, key: 'id' },
field: 'course_id'
}
},
{
sequelize,
createdAt: false,
updatedAt: false,
tableName: 'students_select_courses'
}
)第三步:建立多对多的联系
Student.belongsToMany(Course, {
through: StudentCourse,
foreignKey: 'student_id',
otherKey: 'course_id'
})
Course.belongsToMany(Student, {
through: StudentCourse,
foreignKey: 'course_id',
otherKey: 'student_id'
})第四步:执行多对多查询操作:
async function queryStudent() {
// 查询结果
const result = await Student.findAll({
include: { model: Course }
})
console.log(result)
}
queryStudent()连接池